
What is Kafka?
필자가 맡고있는 서비스에 Elastic Stack 을 도입하면서 중간에 버퍼가 필요하여 Message-Queue 시스템들을 알아보던 중 Kafka 에 대해 알아보고, 정리를 해보게 된다.

# 기본설명 및 기존 메세징 시스템과 다른점
- 메세징 큐의 일종
- 말 그대로
분산형 스트리밍 플랫폼, LinkedIn에서 여러 구직 + 채용 정보들을 한곳에서 처리(발행/구독)할수 있는 플랫폼으로 개발이 시작 - 대용량의 실시간 로그 처리에 특화되어 설계된 메시징 시스템, 기존 범용 메시징 시스템대비 TPS가 매우 우수
- 메시지를 기본적으로 메모리에 저장하는 기존 메시징 시스템과는 달리 메시지를 파일 시스템에 저장 → 카프카 재시작으로 인한 메세지 유실 우려 감소
- 기존의 메시징 시스템에서는 broker가 consumer에게 메시지를 push해 주는 방식인데 반해, Kafka는 consumer가 broker로부터 직접 메시지를 가지고 가는 pull 방식으로 동작하기 때문에 consumer는 자신의 처리능력만큼의 메시지만 broker로부터 가져오기 때문에 최적의 성능을 낼 수 있다.
# 카프카 주요 개념
- producer : 메세지 생산(발행)자.
- consumer : 메세지 소비자
- consumer group : consumer 들끼리 메세지를 나눠서 가져간다.offset 을 공유하여 중복으로 가져가지 않는다.
- broker : 카프카 서버를 가리킴
- zookeeper : 카프카 서버 (+클러스터) 상태를 관리하고
- cluster : 브로커들의 묶음
- topic : 메세지 종류
- partitions : topic 이 나눠지는 단위
- Log : 1개의 메세지
- offset : 파티션 내에서 각 메시지가 가지는 unique id
# 카프카는 어떤식으로 돌아가는가
- zookeeper 가 kafka 의 상태와 클러스터 관리를 해준다.
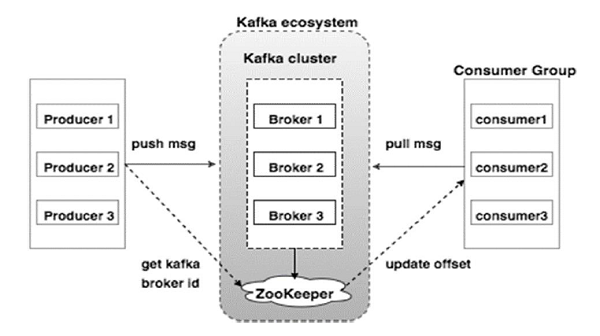
- 정해진 topic 에 producer 가 메세지를 발행해놓으면 consumer 가 필요할때 해당 메세지를 가져간다. (여기서 카프카로 발행된 메세지들은 consumer가 메세지를 소비한다고 해서 없어지는게 아니라 카프카 설정
log.retention.hours(default : 168[7일])에 의해 삭제된다.)
- partition 개수와 consumer group 개념
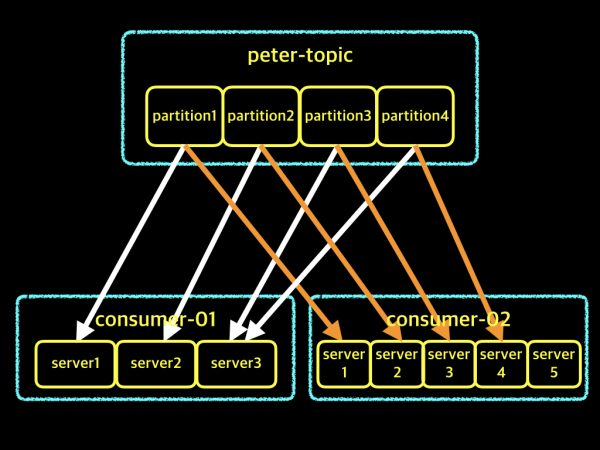
- 하얀색(consumer-01) : 파티션 개수가 4개인데 비해 컨슈머가 3개, 이렇게 되면 어느 컨슈머가 두개의 파티션을 담당해야하는 상황이 생긴다.
- 주황색(consumer-02) : 파티션 개수가 4개인데 비해 컨슈머가 5개, 이렇게 되면 하나의 노는(?) 컨슈머가 생기는 상황이 생긴다.
- 가장 적절한 개수는 정해지지 않았지만 통상 컨슈머그룹의 컨슈머 개수와 파티션 개수를 동일하게 가져가곤 한다.
# 참고 url
- http://kafka.apache.org/
- http://www.popit.kr/author/peter5236/
- http://jinhokwon.tistory.com/168
- http://programist.tistory.com/entry/Apache-Kafka-클러스터링-구축-및-테스트
- https://www.elastic.co/kr/blog/just-enough-kafka-for-the-elastic-stack-part1
- https://www.slideshare.net/springloops/apache-kafka-intro20150313springloops-46067669
